How To setup a Failover Syslog Server
Article created 2006-02-01 by Timm Herget.
You want to have an alternative syslog server for forwarding your e.g. PIX-syslog-messages, which automatically detects if the primary server is alive or not and if not he takes it’s roll until he is back? Here we go:
At first please make sure, that you have installed 2 MonitorWareAgent’s on 2 different machines and have configured the device which forwards syslog to them so, that it sends its data to both of them. Rainer Gerhards also wrote an Article about this, which you can read here.
Pre-Note: Make sure you press the “Save” button after every step – otherwise your changes will not be applied!
Configuring the Primary Server
Step 1:
Create a ruleset on the primary server (machine 1), which contains a “Forward Syslog” action and has no filter conditions configured. Type in the central-server-name to which the logs should be forwarded and leave all other settings default:
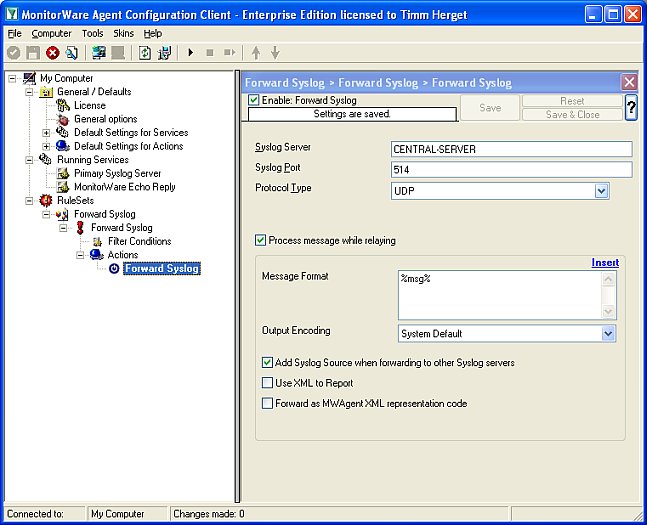
Figure1: creating the ruleset
Step 2:
Now create the primary syslog server service for which you have made the ruleset in step1 and bind it to the ruleset:
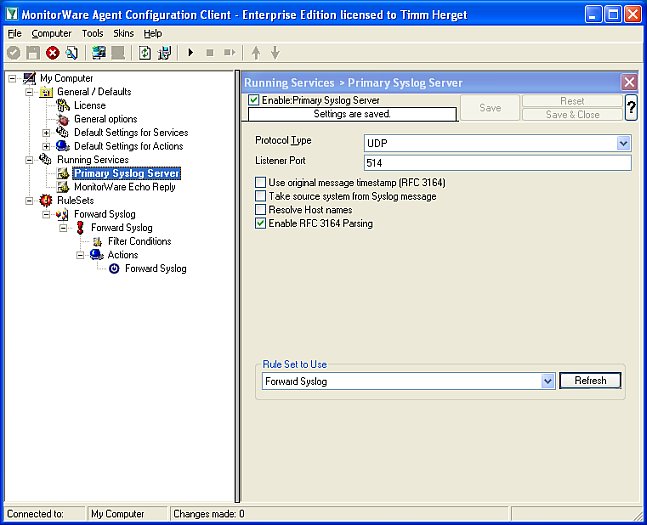
Figure2: creating the syslog server service Step 3:
At last we must create a “MonitorWare Echo Reply” service on the primary server, we will explain later for what:
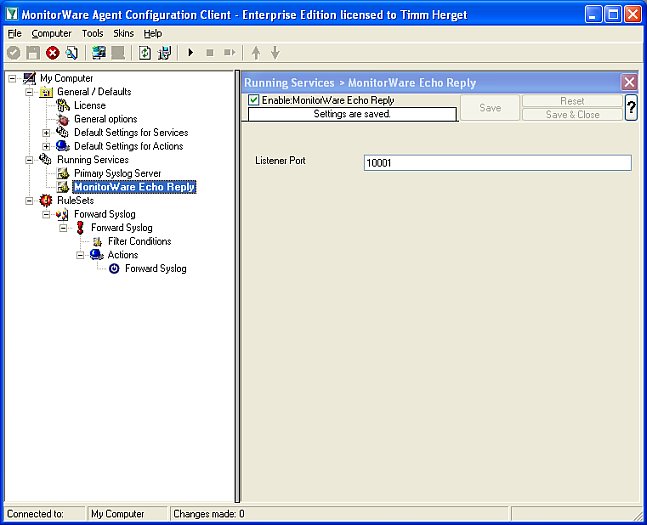
Figure3: creating the monitorware echo reply
Configuring the Secondary Server
Step 1:
Create a ruleset on the secondary server (machine 2), with 1 rule named “Echo Request Successful”. Create a “Set Status” Action in it, set the property name to “ServerActive” and the property value to “1” (without the quotes). We need this to clarify later if the primary-server is active or not and if it is, we set the variable serveractive to 1 which means true.

Figure1: creating the first rule
Step 2:
Now set a message contains filter inside this first rule’s filter conditions. Check the Message to contain: “MWEchoRequest success target“:

Figure2: filter conditions for first rule
Step 3:
We have to create the second rule into the above created echo-request-ruleset now. Again we need to configure a “Set Status” Action and set the property name to “ServerActive” and the property value to “0” now, for the case that the primary server is no longer active:

Figure3: creating the second rule
Step 4:
Again we have to set the filter settings for this case: Check the Message to contain: “MWEchoRequest fail target“:

Figure4: filter conditions for second rule
Step 5:
Now we must create the “MonitorWare Echo Request” service for which we have configured the rule set with its two rules above. Set the check interval to 5 seconds, check “Also generate an event if echo reply was successful” and press “Insert” button to insert a new machine to be requested. In “IP / Hostname” field, type in the ip/hostname of the primary server and let the port default “10001”, assign the service to the “Echo Request Rule” ruleset we created for it:

Figure5: configuring the MonitorWare echo request service
Step 6:
Now let us create a new Rule Set, not a 3rd rule in the ruleset we created for the echo request! Create a forward syslog action in it, type in the name of your CENTRAL-SERVER where the logs should be sent to after this is finished (not the primary server) and leave all other settings default:

Figure6: create rule forward-syslog
Step 7:
Check the filter conditions for the forward syslog ruleset now. Create a “Status Name and Value” filter by right-clicking on the AND, then “Add Filter” -> “General” -> “Status Name and Value”:

Figure7: creating the filters. part 1
Step 8:
Now we have to configure the newly created “Status Name and Value” filter by setting the property name to our global status variable we named “ServerActive”, the compare operation to “is equal” and the property value to “0” (for the case that the primary server is NOT active, because only then this server should do its job):

Figure8: creating the filters. part 2
Step 9:
Create the secondary syslog server service now, let all settings at default values and just assign it to the “Forward Syslog” ruleset:

Figure9: creating the secondary syslog server
Step 10:
The last thing we have to do is to start both MWAgent’s, the one on machine 1 (primary server) and the one on machine 2 (secondary server):

Figure10: start the 2 MWAgent’s
Downloads:
Here are sample configs for the primary and secondary server in *.reg file’s:
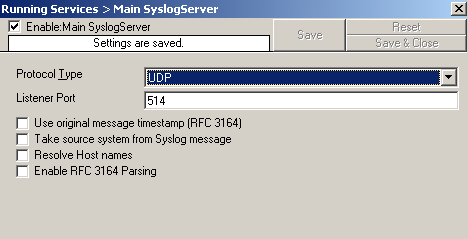 1. Reconfigure your Syslog Server configuration and disable the following options:
1. Reconfigure your Syslog Server configuration and disable the following options: